
Our website uses cookies to enhance your browsing experience.

Rather, how to get down from it. But first things first. This article stands out a bit of the usual format of articles from PVS-Studio. We often write about checking other projects, but almost never lift the veil on our inner workings. It's time to rectify this omission and talk about how the analyzer is built from the inside. More precisely, about the most important of its parts - the syntax tree. The article will focus on the part of PVS-Studio that relates to the C and C++ languages.

The syntax tree is the central part of any compiler. One way or another, the code needs to be presented in a form convenient for program handling, and it just so happens that the tree structure is best suited for this. I will not delve into the theory here - suffice it to say that the tree very well reflects the hierarchy of expressions and blocks in the code, and at the same time contains only the data necessary for work.
What does the compiler have to do with the static analyzer? The fact is that these two tools have a lot in common. At the initial stage of parsing the code, they do the same job. First, the code is divided into a stream of tokens, which is fed to the parser. Then, in the process of synthetic and semantic analysis, tokens are organized into a tree, which is sent further along the pipeline. At this stage, compilers can perform intermediate optimizations before generating binary code, static analyzers begin traversing nodes and launching various checks.
In the PVS-Studio analyzer with a tree built, several things happen:
If you are interested in the details of how the analysis works, I recommend reading the article "Technologies used in the PVS-Studio code analyzer for finding bugs and potential vulnerabilities". Some points from the list are covered there in detail.
We will look in more detail what happens to the tree inside the analyzer, and how it looks in general. At this point a brief introduction is over, it's time to get to the crux of the matter.

Historically, PVS-Studio uses a binary tree to represent code. This classic data structure is familiar to everyone - we have a node that generally refers to two child ones. I will call nodes that are not supposed to have descendants - terminals, all others - nonterminals. A nonterminal may in some cases not have child nodes, but its key difference from the terminal is that descendants are fundamentally allowed for it. Terminal nodes (or leaves) lack the ability to refer to something other than the parent.
The structure used in PVS-Studio is slightly different from the classical binary tree - this is necessary for convenience. Terminal nodes usually correspond to keywords, variable names, literals, and so on. Non-terminals - various types of expressions, blocks of code, lists, and alike constituent elements of a tree.
With regard to compilers design, everything here is pretty standard. I encourage all interested to check out the iconic "Dragon Book".
As for us, we move on. Let's look at a simple code example and how the analyzer perceives it. Further there will be many pictures from our internal tree visualization utility.
So here is the example:
int f(int a, int b)
{
return a + b;
}Being handled by the parser this simple function will look like this (non-terminal nodes are highlighted in yellow):
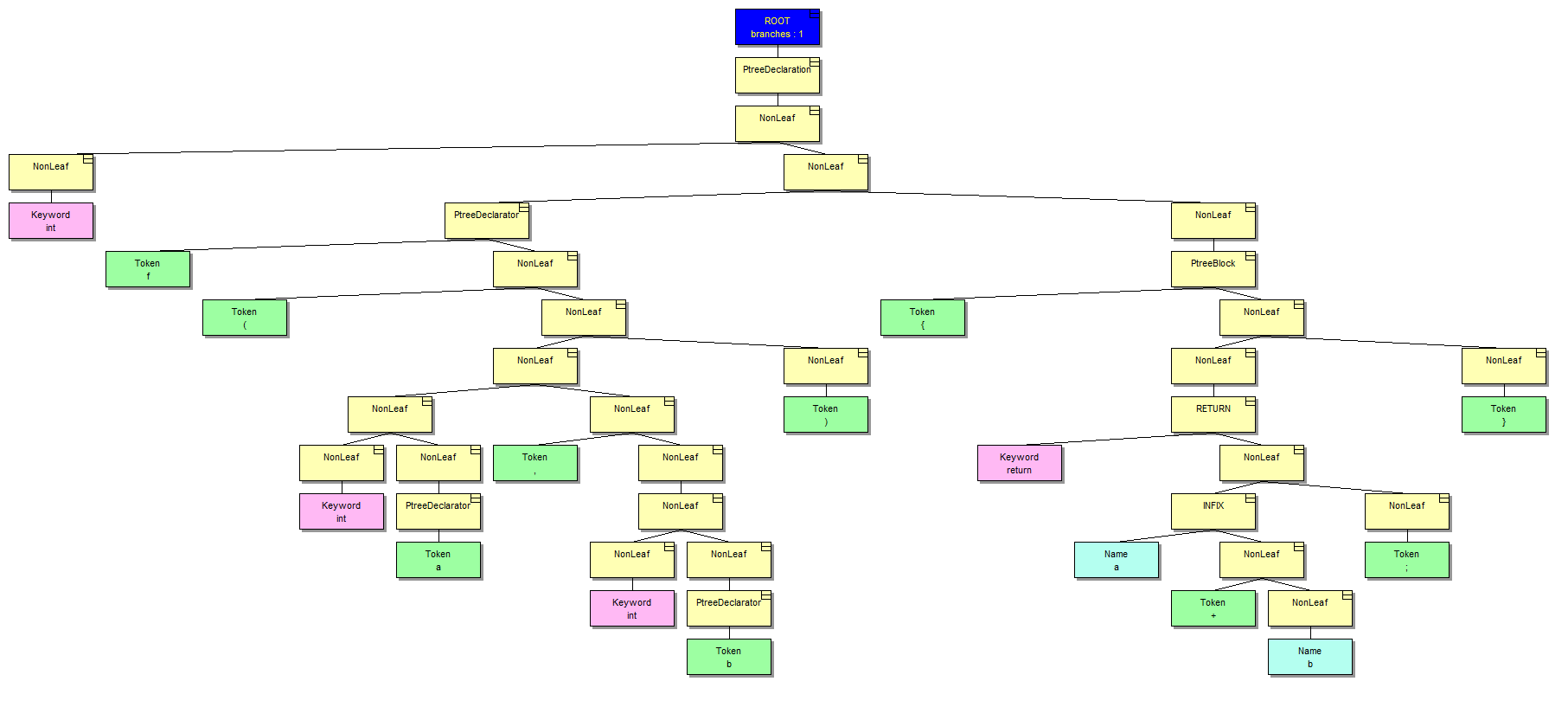
Such representation has its pros and cons. Cons, in my opinion, outnumber the pros. Anyway, let's look at the tree itself. I hasten to say that it is rather redundant, for example, as it contains punctuation and parentheses. The compiler considers it as superfluous garbage, but the analyzer might need this information for some diagnostic rules. In other words, the analyzer does not work with the abstract syntax tree (AST), but with the derivation tree (DT).
The tree grows from left to right and from top to bottom. Left child nodes always contain something meaningful, such as declarators. If we look at the right part of it, we'll see intermediate nonterminals marked by the word NonLeaf. They are only needed for the free to retain its structure. Such nodes don't convey any informational load for the analysis needs.
At this point, we're interested in the left part of the tree. Here it is in a larger closeup:
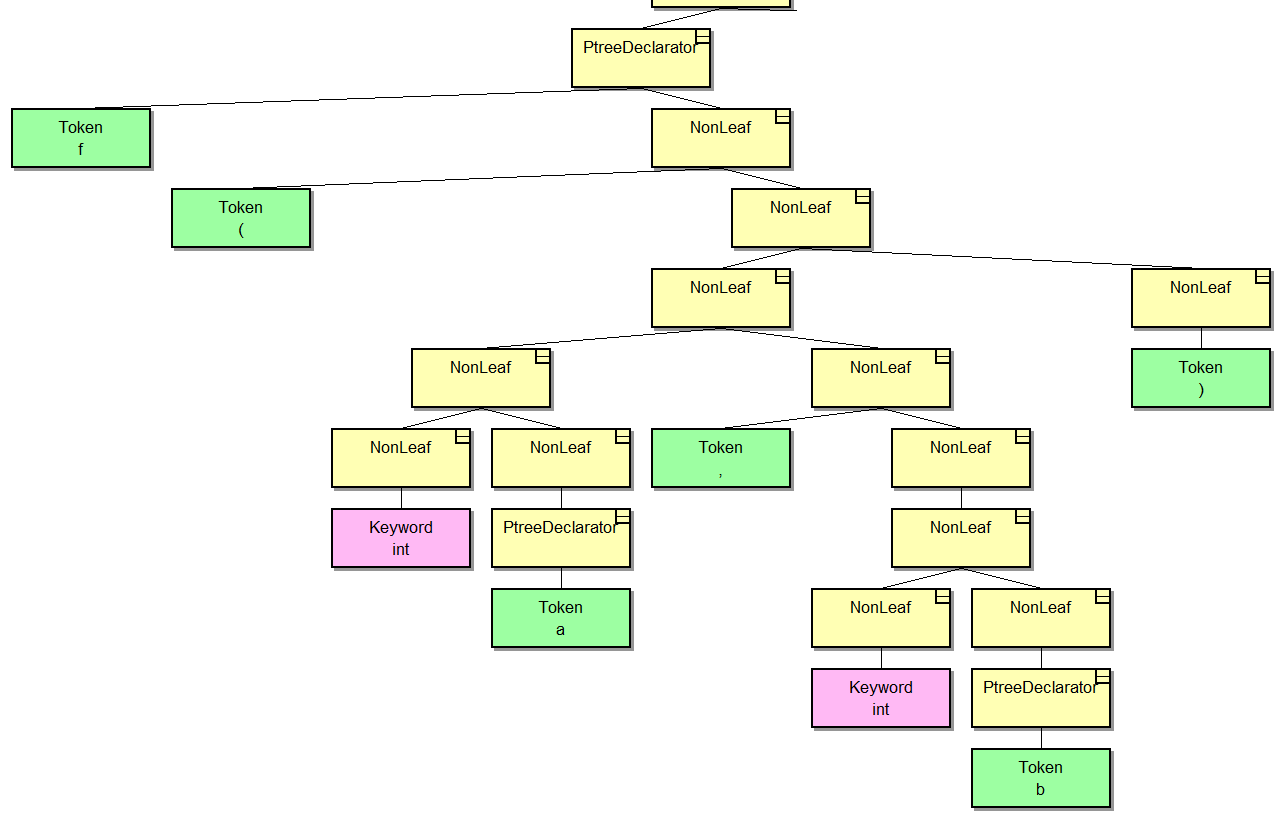
This is a function declaration. The PtreeDeclarator parent node is an object through which you can access nodes with the name of the function and its parameters. It also stores the encoded signature for the type system. It seems to me that this picture is pretty self-explanatory, and it's pretty easy to compare the elements of the tree with the code.
Looks simple, right?
For more clarity, let's take a simpler example. Imagine that we have the code that calls our f function:
f(42, 23);The function call in the tree will look like this:
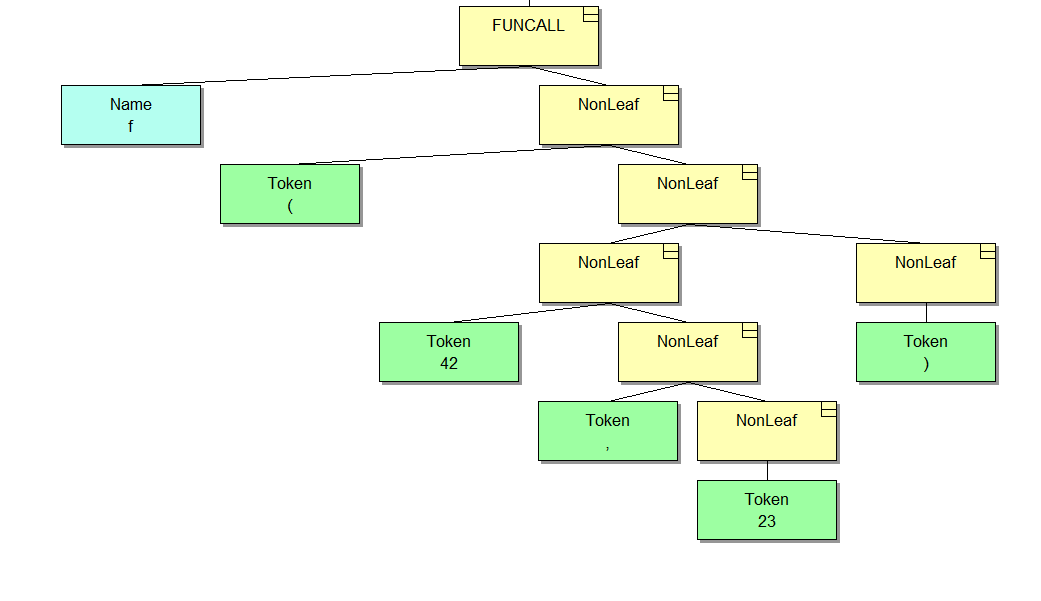
The structure is very similar, only here we see the function call instead of its declaration. Now suppose we wanted to go through all the arguments and do something with each of them. This is a real task that is often found in analyzer code. Needless to say, all this doesn't revolve around arguments, so different types of nodes have to be traversed. But right now we'll consider this specific example.
Suppose we only have a pointer to the parent FUNCALL node. From any nonterminal, we can get the left and right child nodes. The type of each of them is known. We know the structure of the tree, therefore we can immediately get to the node with the list of arguments, which is the NonLeaf, from which the terminal 42 grows (as shown in the picture). We don't know the number of arguments in advance, and there are commas in the list that in this case are absolutely not of interest to us.
How will we do this? Keep reading.
It would seem that iterating along the tree is quite simple. You just need to write a function that will do just that, and use it everywhere. Perhaps, also pass it a lambda as an argument to handle each element. It really would be so, if not for a couple of nuances.
Firstly, every time traversing the tree has to be a little different. The logic of handling each node is different, as well as the logic of working with the entire list. Say, in one case, we want to go through the list of arguments and pass each of them to a certain function for handling. In another, we want to select and return one argument that meets some requirements. Or filter the list and discard any uninteresting elements from it.
Secondly, sometimes you need to know the index of the current element. For example, we want to handle only the first two arguments and stop.
Third, let's digress from the function example. Let's say we have a code fragment like this:
int f(int a, int b)
{
int c = a + b;
c *= 2;
if (c < 42) return c;
return 42;
}I know, this code is dullish, but let's concentrate now on how the tree looks. We have already seen the function declaration, here we need its body:

This case is like a list of arguments, but you might notice some difference. Take another look at the picture from the previous section.
Did you notice something?
That's right, there are no commas in this list, which means that you can process it in a row and not worry about skipping separators.
In total, we have at least two cases:
Now let's see how all this operates in the analyzer code. Here is an example of traversing the list of arguments. This is a simplified version of one of the functions in the translator.
void ProcessArguments(Ptree* arglist)
{
if (!arglist) return;
Ptree* args = Second(arglist);
while (args)
{
Ptree* p = args->Car();
if (!Eq(p, ','))
{
ProcessArg(p);
}
args = args->Cdr();
}
}If I were paid a dollar every time I see such code, I would already get rich.
Let's see what is happening here. I should warn you, this is very old code written long before even C++11, not to mention more modern standards. I guess, I was specifically looking for a fragment of the times of ancient civilizations.
So, firstly, this function accepts the list of arguments in parentheses as input. Something like that:
(42, 23)
The Second function is called here to get the contents of the parentheses. All that it does is shifting once to the right and then once to the left through the binary tree. Next, the loop sequentially gets the elements: 42, then a comma, then 23, and in the next step, the args pointer becomes null, because we get to the end of the branch. The loop, of course, skips uninteresting commas.
Similar functions with slightly changed logic can be found in many places, especially in the old code.
Another example. How do I know if there is a call to a certain function in a certain block of code? Somehow as follows:
bool IsFunctionCalled(const Ptree* body, std::string_view name)
{
if (!arglist) return;
const Ptree* statements = body;
while (statements)
{
const Ptree* cur = statements->Car();
if (IsA(cur, ntExprStatement) && IsA(cur->Car(), ntFuncallExpr))
{
const Ptree* funcName = First(cur->Car());
if (Eq(funcName, name))
return true;
}
statements = statements->Cdr();
}
return false;
}Note. An attentive reader might have noticed something. So where is it old? There is std::string_view sticking out. It's plain and simple, even the oldest code is gradually refactored and eventually nothing of this kind will remain.
It would be nice to use something more elegant here, right? Well, for example, the standard find_if algorithm. In fact, even a regular range-based for would greatly improve readability and facilitate the maintaining of such code, not to mention the algorithm.
Let's try to achieve this.
Our goal is to make the tree behave like an STL container. In doing so, we should not care about the internal structure of the lists, we want to uniformly iterate through the nodes, for example, like this:
void DoSomethingWithTree(const Ptree* tree)
{
....
for (auto cur : someTreeContainer)
{
....
}
}As you can see, here we have a certain entity called someTreeContainer, which we do not know about yet. Such a container should have at least begin and end methods that return iterators. Speaking of iterators, they should also behave like standard ones. Let's start right with them.
In the simplest case, the iterator looks like this:
template <typename Node_t,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int>>
class PtreeIterator
{
public:
using value_type = Node_t;
using dereference_type = value_type;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeIterator(Node_t* node) noexcept : m_node{ node } {}
....
PtreeIterator& operator++() noexcept
{
m_node = Rest(m_node);
return *this;
}
dereference_type operator*() const noexcept
{
return static_cast<dereference_type>(First(m_node));
}
private:
Node_t* m_node = nullptr;
};In order not to clutter the code, I removed some details. The key points here are the dereferencing and the increment. The template is needed so that the iterator can work with both constant and non-constant data.
Now we will write the container in which we will place the tree node. Here is the simplest option:
template <typename Node_t>
class PtreeContainer
{
public:
using Iterator = PtreeIterator<Node_t>;
using value_type = typename Iterator::dereference_type;
using size_type = size_t;
using difference_type =
typename Iterator::difference_type;
public:
PtreeContainer(Node_t* nodes) :
m_nodes{ nodes }
{
if (IsLeaf(m_nodes))
{
m_nodes = nullptr;
}
}
....
Iterator begin() const noexcept
{
return m_nodes;
}
Iterator end() const noexcept
{
return nullptr;
}
bool empty() const noexcept
{
return begin() == end();
}
private:
Node_t* m_nodes = nullptr;
};Ok, we are done, we can all rest easy, thanks for your attention.
No, hold on. It can't be that simple, right? Let's go back to our two list variants - with and without separators. Here, when incrementing, we simply take the right node of the tree, so this does not solve the problem. We still need to skip commas if we want to work only with data.
Not a problem, we just add an additional template parameter to the iterator. For instance, as follows:
enum class PtreeIteratorTag : uint8_t
{
Statement,
List
};
template <typename Node_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int> = 0>
class PtreeIterator { .... };How can this help us? As easy as pie. We will check this parameter in the increment operator and behave accordingly. Fortunately, in C++ 17 we can solve this at compile time using the if constexpr construct:
PtreeIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
return *this;
}That's better, now we can choose an iterator to meet our needs. What shall we do with containers? You can, for example, do something like this:
template <typename Node_t, PtreeIteratorTag tag>
class PtreeContainer
{
public:
using Iterator = PtreeIterator<Node_t, tag>;
....
};Ok, are we done yet? Actually, not really.
Let's look at this code:
void ProcessEnum(Ptree* argList, Ptree* enumPtree)
{
const ptrdiff_t argListLen = Length(argList);
if (argListLen < 0) return;
for (ptrdiff_t i = 0; i < argListLen; ++i)
{
std::string name;
Ptree* elem;
const EGetEnumElement r = GetEnumElementInfo(enumPtree, i, elem, name);
....
}
}I really don't like a lot in this code, starting from the loop with a counter, and ending with the fact that the GetEnumElementInfo function looks very suspicious. At the moment it remains a black box for us, but we can assume that it gets the enum element by index and returns its name and node in the tree via out-parameters. The return value is also a bit strange. Let's get rid of it at all - it's an ideal job for our list iterator:
void ProcessEnum(const Ptree* argList)
{
for (auto elem : PtreeContainer<const Ptree, PtreeIteratorTag::List>(argList))
{
auto name = PtreeToString(elem);
....
}
}Not bad. The snag is that the code doesn't compile. Why? Because the index we removed was used in the body of the loop below the GetEnumElementInfo call. I will not say here exactly how it was used, because it is not crucial now. Suffice it to say that an index is needed.
Well, let's add a variable and mess up our beautiful code:
void ProcessEnum(const Ptree* argList)
{
size_t i = 0;
for (auto elem : PtreeContainer<const Ptree, PtreeIteratorTag::List>(argList))
{
auto name = PtreeToString(elem);
....
UseIndexSomehow(i++);
}
}Still a working option, but this is how I personally react to something like this:

Well, let's try to solve this problem. We need something that can count elements automatically. Let's add an iterator with a counter. I again skipped extra details for brevity:
template <typename Node_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int>>
class PtreeCountingIterator
{
public:
using size_type = size_t;
using value_type = Node_t;
using dereference_type = std::pair<value_type, size_type>;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeCountingIterator(Node_t* node) noexcept : m_node{ node } {}
....
PtreeCountingIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
++m_counter;
return *this;
}
dereference_type operator*() const noexcept
{
return { static_cast<value_type>(First(m_node)), counter() };
}
private:
Node_t* m_node = nullptr;
size_type m_counter = 0;
};Now we can write such code, right?
void ProcessEnum(const Ptree* argList)
{
for (auto [elem, i] :
PtreeCountedContainer<const Ptree, PtreeIteratorTag::List>(argList))
{
auto name = PtreeToString(elem);
....
UseIndexSomehow(i);
}
}Generally speaking, we definitely can, but there is still one problem. If you look at this code, you may notice that we introduced yet another entity - something named PtreeCountedContainer. It seems that the situation is getting more sophisticated. What I really don't want to do is to juggle with different types of containers and given that they are the same inside, the hand itself reaches for the Occam's razor.
We'll have to use the iterator as a template parameter for the container, but more on that later.
Let's distract from counters, types, and iterators for a minute. In pursuit of a universal traverse of nodes, we forgot about the most significant thing - the tree itself.
Take a look at this code:
int a, b, c = 0, d;What we see in the tree:
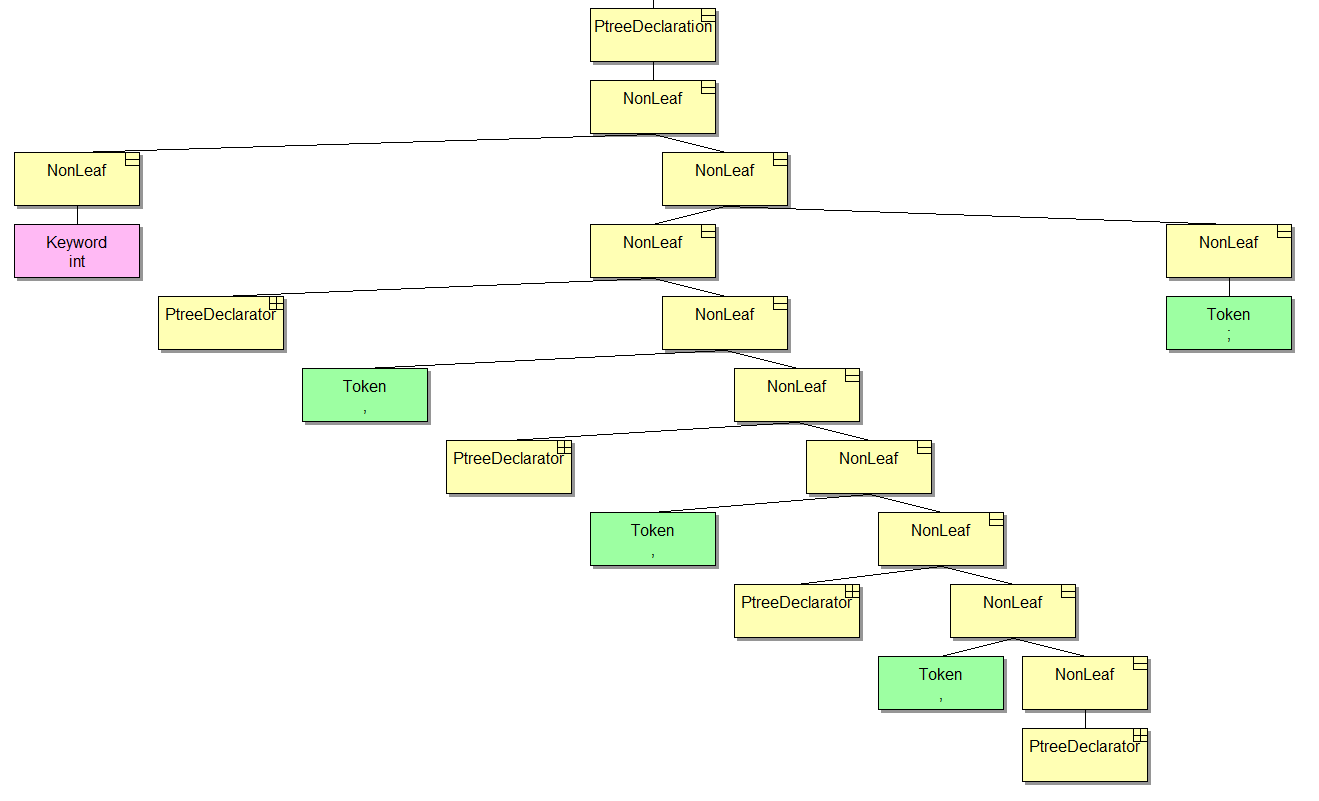
Let's now iterate over the list of declarators, but first I will tell you something else about the tree. All the time before that, we were dealing with a pointer to the Ptree class. This is the base class from which all other types of nodes are inherited. Through their interfaces we can get additional information. In particular, the topmost node in the picture can return to us the list of declarators without using utility functions such as First and Second. Also, we won't need Car and Cdr low-level methods (hi to fans of the Lisp language). This is good news, since in diagnostics we can ignore the implementation of the tree. I think everyone agrees that leaking abstractions are very bad.
This is how traversing of all declarators looks like:
void ProcessDecl(const PtreeDeclarator* decl) { .... }
void ProcessDeclarators(const PtreeDeclaration* declaration)
{
for (auto decl : declaration->GetDeclarators())
{
ProcessDecl(static_cast<const PtreeDeclarator*>(decl));
}
}The GetDeclarators method returns an iterable container. In this case, its type is PtreeContainer<const Ptree, PtreeIteratorTag::List>.
All fine and dandy, except for the cast. The fact is that the ProcessDecl function wants a pointer to a class derived from Ptree, but our iterators know nothing about it. I'd like to avoid converting types manually.
Seems like it's time we changed the iterator and added it the ability to cast.
template <typename Node_t, typename Deref_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int>>
class PtreeIterator
{
public:
using value_type = Deref_t;
using dereference_type = value_type;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
....
}In order not to write all these template arguments manually each time, we will add several aliases for all occasions:
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::List>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::List>;That's better. Now, if we don't need the cast, we can specify only the first template argument. We also don't have to cram our heads with the value of the tag parameter.
What shall we do with containers? To recap, we want to have only one universal class that is suitable for any iterator. What we have here is a ridiculously great number of different combinations, whereas we need simplicity. Something like this:
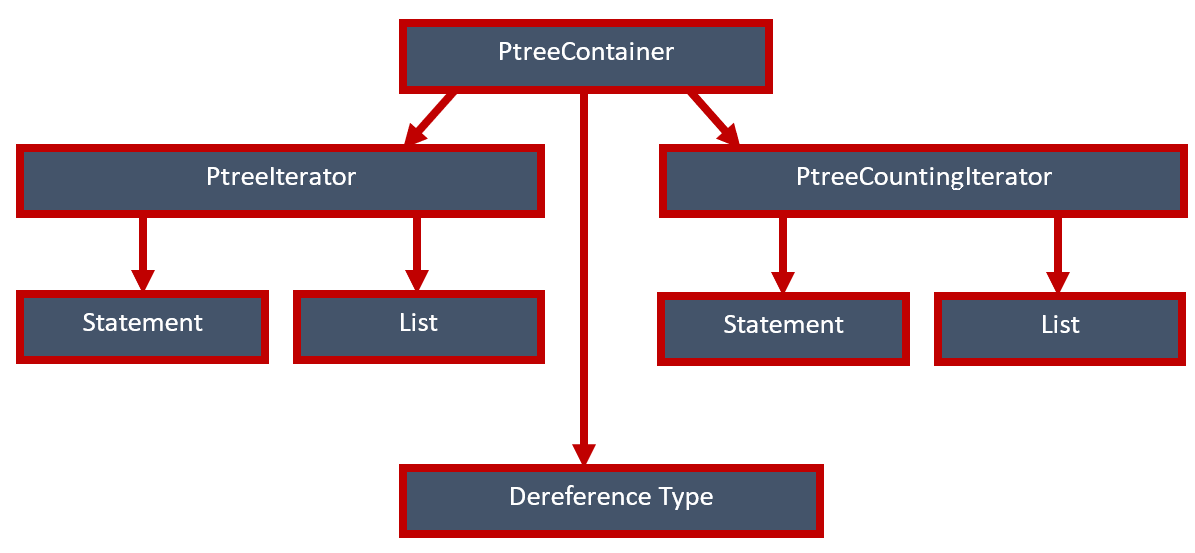
That is, we want a single container class to be able to support all types of our iterators and be able to tell them which type to return when dereferencing. Then, in the code, we simply create the container we need and start working with it without a thought of which iterators we need.
We will address this question in the next section.
So here is what we need:
First of all, we need to somehow bind the container type to the iterator type through template parameters. Here's what we finally got:
template <template <typename, typename> typename FwdIt,
typename Node_t,
typename Deref_t = std::add_pointer_t<Node_t>>
class PtreeContainer
{
public:
using Iterator = FwdIt<Node_t, Deref_t>;
using value_type = typename Iterator::dereference_type;
using size_type = size_t;
using difference_type = typename Iterator::difference_type;
public:
PtreeContainer(Node_t* nodes) :
m_nodes{ nodes }
{
if (IsLeaf(m_nodes))
{
m_nodes = nullptr;
}
}
....
Iterator begin() const noexcept
{
return m_nodes;
}
Iterator end() const noexcept
{
return nullptr;
}
bool empty() const noexcept
{
return begin() == end();
}
....
private:
Node_t* m_nodes = nullptr;
};Also, you can add more methods in the container. For example, this is how we can find out the number of elements:
difference_type count() const noexcept
{
return std::distance(begin(), end());
}Or here is the indexing operator:
value_type operator[](size_type index) const noexcept
{
size_type i = 0;
for (auto it = begin(); it != end(); ++it)
{
if (i++ == index)
{
return *it;
}
}
return value_type{};
}Clearly, one has to handle such methods carefully because of their linear complexity, but sometimes they are useful.
For ease of use, we'll add aliases:
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementList =
PtreeContainer<PtreeStatementIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeItemList =
PtreeContainer<PtreeListIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedStatementList =
PtreeContainer<PtreeStatementCountingIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedItemList =
PtreeContainer<PtreeListCountingIterator, Node_t, Deref_t>;Now we can create containers easily. Say, in the already mentioned PtreeDeclaration class, we want to get a container from the GetDeclarators method, the iterator of which skips separators, while there is no counter in it, and when dereferenced, it returns a value of the PtreeDeclarator type. Here is the declaration of such a container:
using DeclList =
Iterators::PtreeItemList<Ptree, PtreeDeclarator*>;
using ConstDeclList =
Iterators::PtreeItemList<const Ptree, const PtreeDeclarator*>;Now we can write such code and not think about the type of a list, or casts:
void ProcessDecl(const PtreeDeclarator* decl) { .... }
void ProcessDeclarators(const PtreeDeclaration* declaration)
{
for (auto decl : declaration->GetDeclarators())
{
ProcessDecl(decl);
}
}And finally, since type inference for aliases will appear only in C++ 20, in order to more conveniently create containers in the code, we added such functions:
template <typename Node_t>
PtreeStatementList<Node_t> MakeStatementList(Node_t* node)
{
return { node };
}
template <typename Node_t>
PtreeItemList<Node_t> MakeItemList(Node_t* node)
{
return { node };
}
template <typename Node_t>
PtreeCountedStatementList<Node_t> MakeCountedStatementList(Node_t* node)
{
return { node };
}
template <typename Node_t>
PtreeCountedItemList<Node_t> MakeCountedItemList(Node_t* node)
{
return { node };
}Let's recall the function that worked with enums. Now we can write it like this:
void ProcessEnum(const Ptree* argList)
{
for (auto [elem, i] : MakeCountedItemList(argList))
{
auto name = PtreeToString(elem);
....
UseIndexSomehow(i);
}
}Compare with the original version. It seems to me, it has become a way better:
void ProcessEnum(Ptree* argList, Ptree* enumPtree)
{
const ptrdiff_t argListLen = Length(argList);
if (argListLen < 0) return;
for (ptrdiff_t i = 0; i < argListLen; ++i)
{
std::string name;
Ptree* elem;
const EGetEnumElement r = GetEnumElementInfo(enumPtree, i, elem, name);
....
UseIndexSomehow(i);
}
}That's all for me, thank you for your attention. I hope you found out something interesting or even useful.
From the content of the article, it may seem that I am scolding the code of our analyzer and want to say that everything is bad there. But it is not so. Like any project with a history, our analyzer is full of geological deposits that have remained from past eras. Consider that we have just excavated, pulled out the artifacts of ancient civilization from underground and carried out restoration to make them look good on a shelf.
There will be a lot of code here. I doubted whether to include the implementation of iterators here or not, and in the end I decided to include it so as not to leave anything behind the scenes. If you are not interested in reading the code, here I will say goodbye to you. I wish the rest of you have a good time with templates.
template <typename Node_t, typename Deref_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int> = 0>
class PtreeIterator
{
public:
using value_type = Deref_t;
using dereference_type = value_type;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeIterator(Node_t* node) noexcept : m_node{ node } {}
PtreeIterator() = delete;
PtreeIterator(const PtreeIterator&) = default;
PtreeIterator& operator=(const PtreeIterator&) = default;
PtreeIterator(PtreeIterator&&) = default;
PtreeIterator& operator=(PtreeIterator&&) = default;
bool operator==(const PtreeIterator & other) const noexcept
{
return m_node == other.m_node;
}
bool operator!=(const PtreeIterator & other) const noexcept
{
return !(*this == other);
}
PtreeIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
return *this;
}
PtreeIterator operator++(int) noexcept
{
auto tmp = *this;
++(*this);
return tmp;
}
dereference_type operator*() const noexcept
{
return static_cast<dereference_type>(First(m_node));
}
pointer operator->() const noexcept
{
return &(**this);
}
Node_t* get() const noexcept
{
return m_node;
}
private:
Node_t* m_node = nullptr;
};
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListIterator =
PtreeIterator<Node_t, Deref_t, PtreeIteratorTag::List>;template <typename Node_t, typename Deref_t, PtreeIteratorTag tag,
std::enable_if_t<std::is_base_of_v<Node_t, Ptree>, int> = 0>
class PtreeCountingIterator
{
public:
using size_type = size_t;
using value_type = Deref_t;
using dereference_type = std::pair<value_type, size_type>;
using reference = std::add_lvalue_reference_t<value_type>;
using pointer = std::add_pointer_t<value_type>;
using difference_type =
decltype(std::declval<pointer>() - std::declval<pointer>());
using iterator_category = std::forward_iterator_tag;
public:
PtreeCountingIterator(Node_t* node) noexcept : m_node{ node } {}
PtreeCountingIterator() = delete;
PtreeCountingIterator(const PtreeCountingIterator&) = default;
PtreeCountingIterator& operator=(const PtreeCountingIterator&) = default;
PtreeCountingIterator(PtreeCountingIterator&&) = default;
PtreeCountingIterator& operator=(PtreeCountingIterator&&) = default;
bool operator==(const PtreeCountingIterator& other) const noexcept
{
return m_node == other.m_node;
}
bool operator!=(const PtreeCountingIterator& other) const noexcept
{
return !(*this == other);
}
PtreeCountingIterator& operator++() noexcept
{
if constexpr (tag == PtreeIteratorTag::Statement)
{
m_node = Rest(m_node);
}
else
{
m_node = RestRest(m_node);
}
++m_counter;
return *this;
}
PtreeCountingIterator operator++(int) noexcept
{
auto tmp = *this;
++(*this);
return tmp;
}
dereference_type operator*() const noexcept
{
return { static_cast<value_type>(First(m_node)), counter() };
}
value_type operator->() const noexcept
{
return (**this).first;
}
size_type counter() const noexcept
{
return m_counter;
}
Node_t* get() const noexcept
{
return m_node;
}
private:
Node_t* m_node = nullptr;
size_type m_counter = 0;
};
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::Statement>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeListCountingIterator =
PtreeCountingIterator<Node_t, Deref_t, PtreeIteratorTag::List>;template <template <typename, typename> typename FwdIt,
typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
class PtreeContainer
{
public:
using Iterator = FwdIt<Node_t, Deref_t>;
using value_type = typename Iterator::dereference_type;
using size_type = size_t;
using difference_type = typename Iterator::difference_type;
public:
PtreeContainer(Node_t* nodes) :
m_nodes{ nodes }
{
if (IsLeaf(m_nodes))
{
m_nodes = nullptr;
}
}
PtreeContainer() = default;
PtreeContainer(const PtreeContainer&) = default;
PtreeContainer& operator=(const PtreeContainer&) = default;
PtreeContainer(PtreeContainer&&) = default;
PtreeContainer& operator=(PtreeContainer&&) = default;
bool operator==(std::nullptr_t) const noexcept
{
return empty();
}
bool operator!=(std::nullptr_t) const noexcept
{
return !(*this == nullptr);
}
bool operator==(Node_t* node) const noexcept
{
return get() == node;
}
bool operator!=(Node_t* node) const noexcept
{
return !(*this == node);
}
bool operator==(PtreeContainer other) const noexcept
{
return get() == other.get();
}
bool operator!=(PtreeContainer other) const noexcept
{
return !(*this == other);
}
value_type operator[](size_type index) const noexcept
{
size_type i = 0;
for (auto it = begin(); it != end(); ++it)
{
if (i++ == index)
{
return *it;
}
}
return value_type{};
}
Iterator begin() const noexcept
{
return m_nodes;
}
Iterator end() const noexcept
{
return nullptr;
}
bool empty() const noexcept
{
return begin() == end();
}
value_type front() const noexcept
{
return (*this)[0];
}
value_type back() const noexcept
{
value_type last{};
for (auto cur : *this)
{
last = cur;
}
return last;
}
Node_t* get() const noexcept
{
return m_nodes;
}
difference_type count() const noexcept
{
return std::distance(begin(), end());
}
bool has_at_least(size_type n) const noexcept
{
size_type counter = 0;
for (auto it = begin(); it != end(); ++it)
{
if (++counter == n)
{
return true;
}
}
return false;
}
private:
Node_t* m_nodes = nullptr;
};
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeStatementList =
PtreeContainer<PtreeStatementIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeItemList =
PtreeContainer<PtreeListIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedStatementList =
PtreeContainer<PtreeStatementCountingIterator, Node_t, Deref_t>;
template <typename Node_t, typename Deref_t = std::add_pointer_t<Node_t>>
using PtreeCountedItemList =
PtreeContainer<PtreeListCountingIterator, Node_t, Deref_t>;0
0
0

0