
Our website uses cookies to enhance your browsing experience.

Roslyn is a platform which provides the developer with powerful tools to parse and analyze code. It's not enough just to have these tools, you should also understand what they are needed for. This article is intended to answer these questions. Besides this, you will find details about the static analyzer development which uses Roslyn API.

The knowledge given in this article was gained during the course of working with PVS-Studio static analyzer, the C# part of which was written using the Roslyn API.
The article can be divided into 2 logical parts:
If we split the article into more detailed parts, we can see the following sections:
Note. Additionally, I suggest reading a similar article "Manual on development of Visual Studio 2005-2012 and Atmel Studio plugins in C#"
Roslyn is an open source platform, developed by Microsoft, containing compilers and tools for parsing and analysis of code written in C# and Visual Basic.
Roslyn is used in the Microsoft Visual Studio 2015 environment. Various innovations such as code fixes are implemented by means of the Roslyn platform.
Using the analysis tools provided by Roslyn, you can do a complete code parsing, analyzing all the supported language constructs.
The Visual Studio environment enables the creation of tools embedded in the IDE itself (Visual Studio extensions), as well as independent applications (standalone tools).
The source code of Roslyn is available via a repository at GitHub. This allows you to see the way it works and in case of an error - report it to the developers.
The following way of creating a static analyzer and it's diagnostic rules isn't the only one. There is also the possibility of creating diagnostics based on the use of a standard class DiagnosticAnalyzer. Built-in Roslyn diagnostics use this solution. This enables, for instance, integration with a standard list of Visual Studio errors, the ability to highlight errors in a text editor, and so on. But we should remember that if these processes are inside the devenv.exe process, which is 32-bit, there will be strong limitations on the usage of memory. In some cases it is critical, and will not allow the in-depth analysis of large projects (that very program, Roslyn, for instance). Besides that, in this case Roslyn gives the developer less control to traverse the tree, and it does the paralleling of this process itself.
C# PVS-Studio analyzer is a standalone application, which solves the problem with the restrictions on memory use. On top of this, we get more control over the traversing of a tree; do the paralleling as is necessary, controlling the process of parsing and analyzing the code. As we already had experience in creating an analyzer that works according to this principle, (PVS-Studio C++), we decided to use it when creating the C# analyzer. The integration with Visual Studio environment is similar to the C++ analyzer - we did that also by means of a plugin, calling this standalone-application. Thus, using our groundwork, we managed to create a new analyzer for a new language, bound with the solutions we already had, and embed it in a fully-fledged product - PVS-Studio.
Before doing the analysis itself, we have to get a list of files, whose source code is going to be checked, and also get the entities required for correct analysis. We can think of several steps that should be taken to get the data necessary for the analysis:

Let's discuss each point in detail.
Creating the workspace is essential in getting the solutions or the projects. To create the workspace you should call a static method Create of the MSBuildWorkspace class, which returns the object of an MSBuildWorkspace type.
It's necessary to get the solution when we have to analyze several projects of a solution, or all of them. Then, if you have a solution, it's easy to get the list of all the projects included in it.
To get the solution we use the OpenSolutionAsync of the MSBuildWorkspace object. Finally we get a collection containing the list of projects (i.e. object IEnumerable<Project>).
If there is no necessity to analyze all of the projects, you can get a separate project using the asynchronous method OpenProjectAsync object MSBuildWorkspace. Using this method, we get an object of Project type.
Once we have a list of projects ready for analysis, we can start parsing them. The result of parsing the project should be a list of files for analysis and compilation.
It's simple to get the list of files for the analysis - we use the property Documents of the Project class.
To get the compilation, we use method TryGetCompilation or GetCompilationAsync.
Getting the compilation is one of the key points, as it is used to get the semantic model (more details on this will be given later), needed for a thorough and complex analysis of the source code.
To get the correct compilation, the project must be compiled - there should not be any compilation errors, and all dependencies should be located correctly.
Below is code that demonstrates different ways to obtain project files using the MSBuildWorkspace class:
void GetProjects(String solutionPath, String projectPath)
{
MSBuildWorkspace workspace = MSBuildWorkspace.Create();
Solution currSolution = workspace.OpenSolutionAsync(solutionPath)
.Result;
IEnumerable<Project> projects = currSolution.Projects;
Project currProject = workspace.OpenProjectAsync(projectPath)
.Result;
}These actions shouldn't cause any questions, as we have described them earlier.
The next step is parsing the file. Now we need to get the two entities which the full analysis is based on - a syntax tree and a semantic model. A syntax tree is built on the source code of the program, and is used for the analysis of various language constructs. The semantic model provides information on the objects and their types.
To get a syntax tree (an object of SyntaxTreetype) we use the instance method TryGetSyntaxTree, or method TryGetSyntaxTree of GetSyntaxTreeAsync of Document class.
A semantic model (an object of SemanticModel type) is obtained from the compilation using the syntax tree, which was obtained earlier. To do that we use GetSemanticModel method of Compilation class, taking an object of SyntaxTree type as a required parameter.
The class that will traverse the syntax tree and do the analysis should be inherited from the CSharpSyntaxWalker, which will enable to override the traverse methods of various nodes. By calling the Visit method that takes the root of the tree as a parameter (we use the GetRoot method of the object of SyntaxTree) we start a recursive traverse of the nodes of the syntax tree.
Here is the code, showing the way it can be done:
void ProjectAnalysis(Project project)
{
Compilation compilation = project.GetCompilationAsync().Result;
foreach (var file in project.Documents)
{
SyntaxTree tree = file.GetSyntaxTreeAsync().Result;
SemanticModel model = compilation.GetSemanticModel(tree);
Visit(tree.GetRoot());
}
}Nodes are defined for every language construct. In turn, for every node type there is a method traversing the nodes of a similar type. Thus, adding the handlers (diagnostic rules) to the traverse methods of the nodes, we can analyze only those language constructs that are of interest to us.
An example of an overridden method of node traversing, corresponding to the if statement.
public override void VisitIfStatement(IfStatementSyntax node)
{
base.VisitIfStatement(node);
}By adding the necessary rules to the body of the method, we will analyze all if statements, that we will have in the program code.
A syntax tree is a basic element, essential for code analysis. It is the syntax tree that we move along during the analysis. The tree is built on the code, given in the file, which suggests that each file has its own syntax tree. Besides that it should be noted that a syntax tree is unalterable. Well, technically we can change it by calling an appropriate method, but the result of this work will be a new syntax tree, not an edited version of an old one.
For example, for the following code:
class C
{
void M()
{ }
}The syntax tree will be like this:

Nodes of the tree (Syntax nodes) are marked in blue, tokens (Syntax tokens) - in green.
We can see three elements of a syntax tree that is built by Roslyn on the base of the program code:
Let's have a closer look at these elements, as all of them in one way or another, are used during the static analysis. Some of them are used regularly, and the others - much less often.
Syntax nodes (hereinafter - nodes) are syntactic constructs, such as declarations, statements, expressions, etc. The main workload of an analyzer is related to the handling of the nodes. These are the nodes that we move along, and the diagnostic rules are based on the traverses of the nodes.
Let's have a look at an example of a tree, equal to the expression
a *= (b + 4);In contrast to the previous picture, we have the nodes and commentaries that help us to see which node corresponds to which construction.

A base node type is an abstract class SyntaxNode. This class provides a developer with methods, common for all nodes. Let's enumerate some of the most often used (if something is unclear to you - like SyntaxKind or something like that - no worries, we'll speak about it later)
In addition, a set of properties is defined in the class. Here are some of them:
Let's go back to the types of nodes. Each node, representing a language construct, has its own type, defining a number of properties, simplifying the navigation along the tree and obtaining the required data. These types are numerous. Here are some of them and the way they correspond to the language constructs:
Let's have a look at how to use this knowledge in practice, taking if statement as an example.
Let there be such a fragment in the code:
if (a == b)
c *= d;
else
c /= d;This fragment will be represented as a node of IfStatementSyntax at a syntax tree. Then we can easily get the necessary information, accessing various properties of this class:
In practice, this is the same as in theory:
void Foo(IfStatementSyntax node)
{
ExpressionSyntax condition = node.Condition; // a == b
StatementSyntax statement = node.Statement; // c *= d
ElseClauseSyntax elseClause = node.Else; /* else
c /= d;
*/
}Thus, knowing the type of the node, it is easy to find other nodes in it. A similar set of properties is defined for other types of nodes, characterizing certain constructs - method declarations, for loops, lambdas and so on.
Sometimes it's not enough to know the type of the node. One such case would be prefix operations. For example, we need to pick prefix operations of an increment and decrement. We could check the node type.
if (node is PrefixUnaryExpressionSyntax)But such checks would not be enough, because the operators '!', '+', '-', '~' will also suit the condition, as they are also prefix unary operations. So what should we do?
Here the enumeration SyntaxKind comes to help. All the possible language constructs, its keywords, modifiers and others are defined in this enumeration. Using the members of this enumeration, we can set a specific node type. The following properties and methods are defined to specify the node type in the SyntaxNode class.
Using the methods Kind or IsKind, you can easily determine whether the node is a prefix operation of an increment or decrement:
if (node.Kind() == SyntaxKind.PreDecrementExpression ||
node.IsKind(SyntaxKind.PreIncrementExpression))Personally, I prefer using IsKind method because the code looks cleaner and more readable.
Syntax tokens (hereinafter - tokens) are terminals of the language grammar. Tokens are items which are not subject to further parsing - identifiers, keywords, special characters. During the analysis we work directly with them less often than with the nodes of a tree. However, if you still have to work with tokens, this is usually to get the text representation of the token, or to check its type.
Let's have a look at the expression that we mentioned before.
a *= (b + 4);The figure shows a syntax tree that is obtained from this expression. But here, unlike the previous picture, shows the tokens. We can see the connection between the nodes and the tokens that belong to these nodes.

All tokens are represented by a SyntaxToken value type. That's why, to find what a token really is, we use the previously mentioned methods Kind and IsKind, and enumeration items SyntaxKind.
If we have to get a textual representation of the token, it is enough to refer to the ValueText property.
We can also get the token value (a number, for example, if the token is represented by a numeric literal); we should just refer to the Value property that returns a reference of an Object type. However, to get constant values, we usually use a semantic model and a more convenient method GetConstantValue that we will talk about in the next section.
Moreover, syntax trivia (more details in the next section) are also tied to the tokens (actually - to them, rather than to the nodes).
The following properties are defined to work with syntax trivia:
Consider a simple if statement:
if (a == b) ;This statement will be split into several tokens:
An example of getting the token value:
a = 3;Let literal '3' come as a node to be analyzed. Then we get the text and numeric representation in the following way:
void GetTokenValues(LiteralExpressionSyntax node)
{
String tokenText = node.Token.ValueText;
Int32 tokenValue = (Int32)node.Token.Value;
}Syntax trivia (additional syntax information) are those elements of the tree which won't be compiled into IL-code. These include elements of formatting (spaces, line feed characters), comments, and preprocessor directives.
Consider the following simple expression:
a = b; // CommentHere we can see the following additional syntax information: spaces, single-line comment, an end-of-line character. The connection between additional syntax information and tokens is clearly seen on the figure below.
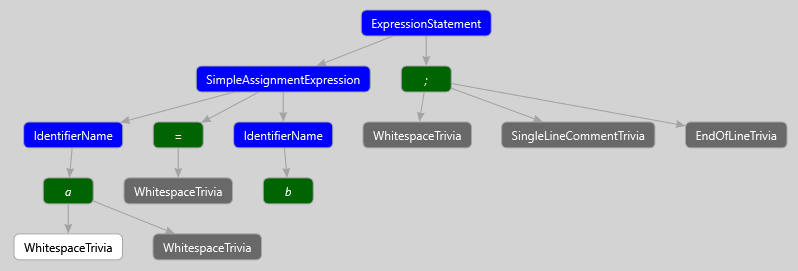
As we have said before, the additional syntax information is connected with tokens. There is Leading trivia, and Trailing trivia. Leading trivia - additional syntax information, preceding the token, trailing trivia - additional syntax information, following the token.
All the elements of additional syntactic information have the type SyntaxTrivia. To define what exactly the element is (a space, single-line, multiline comment or something else) we use the SyntaxKind enumeration and the methods Kind and IsKind.
As a rule, the main work with additional syntactic information is aimed at defining what the elements of it are, and sometimes - to the text analysis.
Suppose we have the following code to analyze:
// It's a leading trivia for 'a' token
a = b; /* It's a trailing trivia for
';' token */Here a single-line comment will be bound to the token 'a', and the multiline comment - to the token ';'.
If we get a=b; expression as a node, it's easy to get the text of a single-line and multiline token like this:
void GetComments(ExpressionSyntax node)
{
String singleLineComment =
node.GetLeadingTrivia()
.SingleOrDefault(p => p.IsKind(
SyntaxKind.SingleLineCommentTrivia))
.ToString();
String multiLineComment =
node.GetTrailingTrivia()
.SingleOrDefault(p => p.IsKind(
SyntaxKind.MultiLineCommentTrivia))
.ToString();
}Summing up the information from this section we can see the following points regarding the syntax tree:
A semantic model provides information on objects, and the types of objects. This is a very powerful tool that allows you to carry out deep and complex analysis. This is why it's very important to ensure correct compilation, and a correct semantic model. Reminder: the project must be a compiled one.
We should also remember that we work with nodes, not objects. That's why neither is operator, nor GetType method, will work to get the information, as they give information about the node, not about the object. Let's analyze the following code, for example.
a = 3;We can only suggest what a is in this expression. It's impossible to say whether it is a local variable, a property, or a field; we can only make an assumption. Yet no one is interested in seeing the guesses, we need exact information.
We could have tried to move up along the tree until we see the variable declaration, but this would be too lavish from the point of view of the performance and the code size. Moreover, this declaration might be located somewhere in a different file, or even in a third-party library, whose source code we don't have.
So, a semantic model is of great use for us here.

We can say that there are three functions used most often, which are provided by a semantic model:
We will speak in detail about these points, as they are really important, and widely used in static analysis.
So-called symbols provide information on an object.
The base interface of the symbol - ISymbol, which provides methods and properties that are common for all the objects, regardless of whether they are - fields, properties, or something else.
There is a number of derived types that a programmer can cast to, to get more specific information about the object. Such methods are IFieldSymbol, IPropertySymbol, IMethodSymbol and others.
For instance, if we use the casting to the interface IFieldSymbol, and address the field IsConst you can find out if the node is a constant filed. If we use the IMethodSymbol interface, we can learn if this method returns any value.
There is also a Kind property that is specified for the symbols, and returns the enumeration elements. This enumeration is similar to the SyntaxKind regarding its meaning. That is, by using the Kind property, you can see what we're working on - a local object, a field, a property, assembly, etc.
For example, suppose you have a following field definition:
private const Int32 a = 10;And somewhere below - the following code:
var b = a;Let's suppose that we need to find out if a is a constant field. Using a semantic model, we can get the necessary information about the a node from the given expression. The code for getting the information will be like this:
Boolean? IsConstField(SemanticModel model,
IdentifierNameSyntax identifier)
{
ISymbol smb = model.GetSymbolInfo(identifier).Symbol;
if (smb == null)
return null;
return smb.Kind == SymbolKind.Field &&
(smb as IFieldSymbol).IsConst;
}First we get a symbol for the identifier, using the GetSymbolInfo method of an object having SemanticModel type, after which we address the Symbol field (it is this field that contains the necessary information, so there is no point in storing the structure SymbolInfo that is returned by GetSymbolInfo).
After the verification against null, using the Kind property which specifies the symbol, we are sure that the identifier is a real field. If it is really so - we'll cast to the derived interface IFieldSymbol, which will allow addressing the IsConst property, and let us get the information about the constancy of the field.
It is often necessary to know the type of the object that is represented by a node. As I wrote before, the is operator and the GetType method are not suitable because they work with the node type, rather than the analyzed object.
Fortunately, there is a way out, and quite a graceful one. You can get the necessary information using the ITypeSymbol interface. To get it we use GetTypeInfo method of an object having SemanticModel type. In general, this method returns the TypeInfo structure that contains two important properties:
Using the ITypeSymbol interface that is returned by these properties, you can get all the information about the type. This information is retrieved due to the access to the properties, some of which are listed below:
We should note that you can see not only the object type, but the entire expression type. For example, you can get the type of the expression a + b, and the types of the variables a and b separately. Since these types may vary, it's very useful during the development of some diagnostic rules to have the possibility of getting the types of the whole expression.
Besides, as for the ISymbol interface, there is a number of derived interfaces, which enable you to get more specific information.
To get the names of all interfaces, implemented by the type and also by the base type, you can use the following code:
List<String> GetInterfacesNames(SemanticModel model,
IdentifierNameSyntax identifier)
{
ITypeSymbol nodeType = model.GetTypeInfo(identifier).Type;
if (nodeType == null)
return null;
return nodeType.AllInterfaces
.Select(p => p.Name)
.ToList();
}It's quite simple, all the methods and properties were described above, so you shouldn't have any difficulties in understanding the code.
A semantic model can also be used to get constant values. You can obtain these values for constant fields, character, string, and numeric literals. We have described how to get constant values, using tokens.
A semantic model provides a more convenient interface for this. In this case we don't need tokens, it is enough to have the node from which you can get a constant value - the model will do the rest. It is very convenient, as during the analysis the main workload is connected with the nodes.
To get constant values we use GetConstantValue method that returns a structure Optional<Object> using which it's very easy to verify the success of the operation, and get the needed value.
For example, suppose you have the following code to analyze:
private const String str = "Some string";If there is a str object somewhere in the code, then, using a semantic model, it's easy to get a string that the field refers to :
String GetConstStrField(SemanticModel model,
IdentifierNameSyntax identifier)
{
Optional<Object> optObj = model.GetConstantValue(identifier);
if (!optObj.HasValue)
return null;
return optObj.Value as String;
}Summing up the information from this section we can see the following points regarding the semantic model:
Syntax visualizer (hereinafter - the visualizer) is an extension for the Visual Studio environment, which is included into the Roslyn SDK (available in Visual Studio Gallery). This tool, as the name suggests, displays the syntax tree.

As you can see on the picture, blue elements are the nodes, green are tokens, red - additional syntax information. Besides that, for each node you can find out the type, Kind value, and values of the properties. There is also a possibility to get the ISymbol and ITypeSymbol interfaces for the nodes of the tree.
This tool is useful indeed in the TDD methodology, when you write a set of unit-tests before the implementation of a diagnostic rule, and only after that start programming the logic of the rule. The visualizer allows easy navigation along the written code; it also allows you to see which node traverse needs to be subscribed to, and where to move along the tree; for which nodes we can (and need) to get the type and the symbol, which simplifies the development process of the diagnostic rule.
There is one more variant for displaying the tree, besides the format that we have just seen. You should open a context menu for the element and choose View Directed Syntax Graph. I got the trees of various syntactic constructs, given in this article, by means of this mechanism.

True life story
Once during the development of PVS-Studio we had a situation where we had a stack overflow. It turned out that one of the projects we were analyzing - ILSpy - had an auto-generated file Parser.cs that contained a crazy amount of nested if statements. As a result, the stack was overflowed during the attempt to traverse the tree. We have solved this problem by increasing the maximum stack size for the threads, where the tree is traversed, but the syntactic visualizer and Visual Studio still crash on this file.
You can check it yourself. Open this awesome file, find this heap of if statements, and try to have a look at the syntax tree (line 3218, for example).
There is a number of rules that should be followed during the development of a static analyzer. Sticking to these rules, you will make a product of a higher quality, and implement functional diagnostic rules.
Searching for errors is mostly done by means of various diagnostic rules. There is usually a set of common actions that should be done, so we can speak about the general algorithm of writing a diagnostic.


In the PVS-Studio static analyzer, there is a diagnostic V3006 that searches for a missing throw statement. The logic is the following - an exception object is created, which is not used in any way (the reference to it isn't passed anywhere, it doesn't return from the method, and so on.) Then most likely, the programmer missed a throw statement. As a result the exception won't be generated, and the object will be destroyed during the next garbage collection.
As we have thought out the rule, we can start writing unit tests.
An example of a positive test:
if (cond)
new ArgumentOutOfRangeException();An example of a negative test:
if (cond)
throw new FieldAccessException();We can point out the following points in the algorithm of the diagnostic's work:
We will give the description of a possible implementation of such this diagnostic rule. I have rewritten the code, and simplified it, to make it easier to understand. But even such a small rule copes with this task and finds real errors.
The general code for searching the missing throw statement:
readonly String ExceptionTypeName = typeof(Exception).FullName;
Boolean IsMissingThrowOperator(SemanticModelAdapter model,
ObjectCreationExpressionSyntax node)
{
if (!IsExceptionType(model, node))
return false;
if (IsReferenceUsed(model, node.Parent))
return false;
return true;
}You can see the steps of the algorithm, described earlier. In the first condition there is a check that the type of object is the exception type. The second check is to determine whether the created object is used or not.
SemanticModelAdapter can be a little confusing. There is nothing tricky here, it's just a wrapper around the semantic model. In this example, it is used for the same purposes as the general semantic model (SemanticModel object type).
Method of checking whether the type is the exception one:
Boolean IsExceptionType(SemanticModelAdapter model,
SyntaxNode node)
{
ITypeSymbol nodeType = model.GetTypeInfo(node).Type;
while (nodeType != null && !(Equals(nodeType.FullName(),
ExceptionTypeName)))
nodeType = nodeType.BaseType;
return Equals(nodeType?.FullName(),
ExceptionTypeName);
}The logic is simple - we get information about the type, and check the whole inheritance hierarchy. If we see in the result that one of the basic types is System.Exception, we think that the type of the object is the exception type.
A method to check that the reference isn't passed anywhere and isn't stored anywhere.
Boolean IsReferenceUsed(SemanticModelAdapter model,
SyntaxNode parentNode)
{
if (parentNode.IsKind(SyntaxKind.ExpressionStatement))
return false;
if (parentNode is LambdaExpressionSyntax)
return (model.GetSymbol(parentNode) as IMethodSymbol)
?.ReturnsVoid == false;
return true;
}We could check if the reference is used, but then we'll have to consider too many cases: return from the method, passing to the method, writing to the variable, etc. It's much easier to have a look at cases where the reference isn't passed anywhere, and not written anywhere. This can be done with the checks that we have already described.
I think the first one is quite clear - we check that the parent node is a simple expression. The second check isn't a secret either. If the parent node is a lambda expression, let's check that the reference is not returned from lambda.
Roslyn is not a panacea. Despite the fact that it is a powerful platform for parsing and analyzing code, it also has some drawbacks. At the same time we see plenty of pluses. So, let's have a look at the points from both categories.
PVS-Studio is a static analyzer for bug detection in the source code of programs, written in C, C++ and C#.
That part of the analyzer, which is responsible for checking the C# code is written on Roslyn API. The knowledge and rules that are described above aren't pulled out of a hat, they are obtained and formulated during the work with the analyzer.
PVS-Studio is an example of a product you can create using the Roslyn. At this point we have more than 80 diagnostics implemented in the analyzer. PVS-Studio has already found a lot of errors in various projects. Some of them:
But the proof of the pudding is in the eating, in our case - it's better to have a look at the analyzer yourself. You can download it here, and see what it will find in your projects.
Some may wonder: "Have you found anything of interest during the checking process?" Yes, we have. Plenty of bugs. If someone thinks that professionals don't make mistakes, I suggest looking at an error base, found in open source projects. Additionally you may read about the checks of various projects in the blog.

Summing up, Roslyn is a really powerful platform, on the base of which you can create different multifunctional tools - analyzers, refactoring tools, and many more. Big thanks to Microsoft for the Roslyn platform, and the chance to use it for free.
However, it's not enough just to have the platform; you must know how to work with it. The main concepts and principles of work are described in this article. This knowledge can help you get a deeper insight into the development process on the Roslyn API, if you wish.
0
0
0

0